自然语言处理(三)GPT-4

自然语言处理(三)
Natural Language Processing(NLP)
我们认为,拥有最大计算机的人将获得最大的收益。
Part 1
NLP
自然语言处理
Natural Language Processing
是人工智能的一个重要领域,它主要研究计算机如何处理自然语言,即人类习惯使用的语言。自然语言处理涉及到语音识别、语义理解、机器翻译等一系列技术,是人工智能领域的基础技术之一。
自然语言处理技术的发展历程可以追溯到20世纪50年代,当时美国国防部门针对战争进行的人工智能研究计划(Project X),提出了自然语言处理这一概念。此后,自然语言处理技术逐渐得到发展,并在语音识别、机器翻译等领域取得了显著成就。目前,自然语言处理技术已经应用于多个领域,例如搜索引擎、社交媒体、客服机器人、智能家居等。例如,在搜索引擎领域,自然语言处理技术可以用于提高搜索结果的准确性,使用户能够通过自然语言的方式提出查询请求,而无需使用特定的关键词。在社交媒体领域,自然语言处理技术可以用于分析用户的评论和反馈,从而提高社交媒体平台的用户体验。在客服机器人领域,自然语言处理技术可以用于实现机器人与用户之间的自然语言交流,从而提升客服服务的效率。在智能家居领域,自然语言处理技术可以用于实现人机交互,让用户可以通过自然语言的方式对智能家居进行控制。
总的来说,自然语言处理技术为人工智能的发展奠定了坚实的基础,它已经应用于多个领域,并取得了显著的成就。随着人工智能技术的进一步发展,自然语言处理技术也将得到进一步完善和提升。

自然语言处理的历史
在20世纪60年代,随着计算机技术的发展,自然语言处理技术也进一步提升。当时,美国国家科学基金会(NSF)成立了“自然语言处理研究计划”,专门用于支持自然语言处理技术的研究。同时,英国也成立了“自然语言处理研究室(Natural Language Processing Research Laboratory)”,专门致力于自然语言处理技术的研究与应用。
在20世纪70年代,自然语言处理技术又迎来了一个新的发展阶段。这一时期,自然语言处理技术发展到了语言学理论与计算机科学相结合的阶段。其中,语义学和句法学等语言学理论成为自然语言处理技术研究的重要基础。
在20世纪80年代,随着人工智能技术的进一步发展,自然语言处理技术也进入了一个新的阶段。这一时期,自然语言处理技术得到了广泛应用,并取得了一系列突破性成果。例如,英国语言工程研究所(LEL)在1983年成功开发出了世界上第一个基于人工智能的翻译系统,该系统能够将英语翻译成法语。
在20世纪90年代,自然语言处理技术进一步发展壮大。随着互联网的普及,自然语言处理技术在搜索引擎、社交媒体、客服机器人等领域得到广泛应用。此外,自然语言处理技术还进入了深度学习阶段,开始使用深度神经网络进行语言模型的建立和训练,从而提升自然语言处理技术的准确性和效率。如今,自然语言处理技术已经成为人工智能领域的重要组成部分,并在多个领域得到广泛应用。
虽然自然语言处理技术还存在一些挑战和问题,但随着人工智能技术的不断发展,自然语言处理技术也将得到进一步完善和提升,为人类的日常生活和工作带来更多的便利和效率。总的来说,自然语言处理技术是人工智能领域的一个重要分支,它为人类沟通与交流提供了便捷的手段。自然语言处理技术的早期发展历程可以追溯到20世纪50年代,并在现在不断发展壮大。随着人工智能技术的进一步发展,自然语言处理技术也将得到更多的应用和提升。

Part 2
GPT-3设计理念和特点
自然语言处理是人工智能的一个重要领域,它主要研究计算机如何处理自然语言,即人类习惯使用的语言。自然语言处理涉及到语音识别、语义理解、机器翻译等一系列技术,是人工智能领域的基础技术之一。
GPT-3
Generative Pretrained Transformer-3
是由OpenAI研发的一种大规模语言模型,它使用了深度学习技术,并结合了自然语言处理技术。GPT-3可以用于各种文本生成任务,包括语音合成、机器翻译、文本摘要、问答系统等。它的出现为自然语言处理技术的应用带来了新的可能,并为人工智能的发展提供了重要的突破。
总的来说,自然语言处理是人工智能领域的基础技术,而GPT-3则是基于自然语言处理技术的一种语言模型,它为自然语言处理技术的应用带来了新的可能。

GPT-4即将到来,OpenAI仍在修复GPT-3
GPT-4是自然语言处理(NLP)算法的最新版本,使用自动学习模型来生成与人类类似的文本,以响应引入的咨询问答。
GPT-3.5 过渡版
您所知道的关于GPT-4的一切
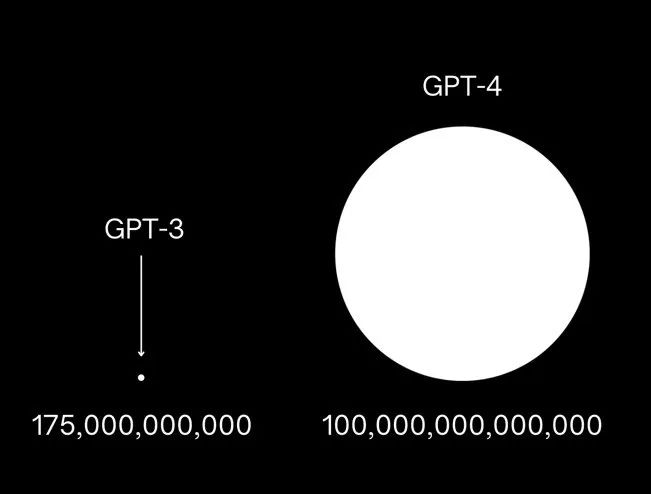
GPT-4将有100万亿个参数,是GPT-3的500倍大小。
OpenAI 的 GPT-3(如果有缺陷的话)非常有能力,它可能是第一个证明人工智能,可以令人信服地,如果不是完美地像人类一样写作的人。GPT-3 的继任者,最有可能称为 GPT-4,预计将在不久的将来亮相,可能最快在 2023 年。
但与此同时,OpenAI 已经悄悄推出了一系列基于“GPT- 3.5”,这是一个先前未宣布的 GPT-3 改进版本。
GPT-3.5在上周三与ChatGPT一起亮相,ChatGPT是GPT-3.5的微调版本,本质上是一个通用聊天机器人。它可以参与一系列主题,包括编程、电视脚本和科学概念。根据OpenAI 的说法,GPT-3.5是在 2021 年第四季度之前发布的混合文本和代码上进行训练的,与GPT-3和其他文本生成 AI 一样,GPT-3.5通过摄取大量信息来学习句子、单词和部分单词之间的关系,来自网络的大量内容包括数十万条维基百科条目、社交媒体帖子和新闻文章。
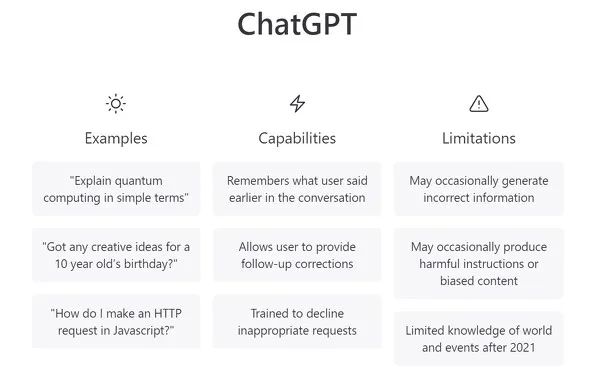
ChatGPT 用户数在 6 天内突破 100 万,据开发该机器人的 OpenAI 首席执行官萨姆奥特曼发布的一条推文称,截至11月30日发布的人工智能聊天机器人“ChatGPT”的用户数量超过 100 万。
更大更好的语言建模
语言建模是一个过程,它允许机器用我们理解的语言来理解我们并与我们交流,甚至可以将自然的人类语言转化为可以运行程序和应用程序的计算机代码。我们看到OpenAI 的 GPT-3,这是有史以来最先进(也是最大)的语言模型,由大约 1750 亿个“参数”组成,机器可以用来处理语言的变量和数据点。众所周知,OpenAI 正在开发更强大的继任者 GPT-4。虽然细节还没有确定,但一些估计它可能包含多达 100 万亿个参数,使其比 GPT-3 大 500 倍,并且在理论上更接近于能够创造语言,并进行与人类无法区分的对话。它在创建计算机代码方面也会变得更好。
OpenAI 的诞生是为了应对,实现通用人工智能 (AGI) 挑战,一种能够做人类能做的任何事情的人工智能
Part 3
OpenAI 应 用
OpenAI是一家总部位于美国加利福尼亚州旧金山的人工智能研究与开发公司。该公司成立于2015年,由硅谷企业家伊隆·马斯克、拉里·佩奇、弗兰克·鲍德温和克雷格·佩奇等人创立。
AI技术将改变我们所知道的世界。如果使用得当,它可以使我们所有人受益,但如果落入坏人之手,它可能成为最具破坏性的武器。OpenAI 的价值观来从事这项任务,以确保它能使每个人都平均受益:“他们的目标是以最有可能,造福全人类的方式推进数字智能。”它可以说是人类所从事的最大的科学事业,近几年来计算机科学和人工智能取得了所向披靡的进步。一些人认为深度学习不足以实现 AGI。伯克利计算机科学教授和人工智能先驱 斯图尔特·拉塞尔 认为,专注于原始计算能力完全没有抓住重点 。
AGI(Artificial General Intelligence)
是人工智能的一种,它指的是一种能够完成人类任何形式智力活动的人工智能。AGI的目标是实现人工智能与人类智能的通用性,即人工智能能够完成任何人类能完成的智力活动,而不局限于某一特定领域。AGI与其他人工智能相比,最大的特点在于其具有通用性。传统的人工智能技术只能在特定的领域取得成功,例如机器学习只能用于模式识别,自然语言处理只能用于文本分析。而AGI能够实现人工智能与人类智能的通用性,它能够适应各种环境。
相比之下,OpenAI 相信以大型数据集为基础,并在大型计算机上训练的大型神经网络是通向 AGI 的最佳途径。OpenAI 的 CTO 格雷格·布罗克曼 在接受英国《金融时报》采访时表示:“我们认为,拥有最大计算机的人将获得最大的收益。”他们就是这么做的。他们开始训练越来越大的模型,以唤醒深度学习中隐藏的力量。朝着这个方向迈出的第一个是 GPT 和 GPT-2 的发布。这些大型语言模型为该项目的明星 GPT-3 奠定基础。一个比 GPT-2 大 100 倍的语言模型,有 1750 亿个参数。
GPT-3 是当时创建的最大的神经网络,并且仍然是最大的密集神经网络。它的语言专业知识和无数的能力,令大多数人感到惊讶。尽管一些专家仍然持怀疑态度,但大型语言模型已经给人一种奇怪的感觉。对于 OpenAI 研究人员来说,这是一个巨大的飞跃。
三位一体:算法、数据和计算机
OpenAI 相信缩放假设,给定一个可扩展的算法,在这种情况下是转换器,GPT 系列背后的基本架构,可能有一条通向 AGI 的直接路径,包括基于该算法训练越来越大的模型。但大型模型只是 AGI 难题的一部分。训练它们需要大量的数据集和大量的计算能力。当机器学习社区开始揭示无监督学习的潜力时,数据不再是瓶颈。这与生成语言模型和少量任务转移一起解决了 OpenAI 的“大型数据集”问题。
他们只需要巨大的计算资源来训练和部署他们的模型,他们就可以开始了。这就是他们在 2019 年与微软合作的原因。他们向这家大型科技公司授权,以便他们可以在商业上使用 OpenAI 的一些模型,以换取对其云计算基础设施和他们所需的强大 GPU 的访问权。但 GPU 并不是专门为训练神经网络而构建的。游戏行业开发了这些用于图形处理的芯片,而人工智能行业只是利用了它在并行计算方面的适用性。OpenAI 想要最好的模型和最好的数据集,他们也想要最好的计算机芯片GPU 是不够的。许多公司也意识到了这一点,并开始构建内部专用芯片来训练神经网络,同时不会降低效率或容量。然而,像OpenAI这样的纯软件公司很难将硬件设计和制造融为一体。这就是为什么他们选择了另一条路线:使用第三方 AI 专用芯片。

这是 Cerebras Systems 进入现场的地方。这家芯片公司已经在 2019 年构建了有史以来最大的芯片来训练大型神经网络。现在他们再次做到了,OpenAI 将充分利用这一惊人的工程。
芯片和模型:WSE-2 ,GPT-4
Cerebras 再次打造了市场上最大的芯片Wafer Scale Engine Two晶圆级引擎二 (WSE-2)。它每边约 22 厘米,有 2.6 万亿个晶体管。相比之下,特斯拉全新的训练块有 1.25 万亿个晶体管。

Cerebras 找到了一种有效压缩计算能力的方法,因此 WSE-2 有 850000 个核心,计算单元而典型的 GPU 有几百个。他们还通过新型冷却系统解决了发热问题,并设法创建了高效的 I/O 数据流。像 WSE-2 这样的超专业、超昂贵、超级强大的芯片并没有太多用途,训练大型神经网络就是其中之一。
大型语言模型将更新到:GPT-4
我们生活在非凡的时代,你会看到一种新型模型的推出,它彻底改变了 AI 领域。2022 年 7 月,OpenAI 推出了DALLE2,这是一种最先进的文本到图像模型。几周后,Stability.AI 推出DALLE-2的开源版本,名为Stable Diffusion。这两种模型都很受欢迎,并且在质量和理解提示的能力方面都显示出可喜的结果。
最近,OpenAI 推出了一种名为Whisper的自动语音识别 (ASR) 模型。它在稳健性和准确性方面优于所有其他模型。
从趋势来看,我们可以假设 OpenAI 将在未来几个月推出 GPT-4。市场对大型语言模型的需求很高,GPT-3 的流行已经证明人们期待 GPT-4 具有更好的准确性、计算优化、更低的偏差和更高的安全性。
尽管 OpenAI 对发布或功能保持沉默,但在这篇文章中,我们将根据 AI 趋势和 OpenAI 提供的信息对 GPT-4 做出一些假设和预测。
什么是 GPT?
Generative Pre-trained Transformer (GPT) 是一种基于互联网可用数据训练的文本生成深度学习模型。它用于问答、文本摘要、机器翻译、分类、代码生成和对话 AI。
您可以通过在 Python技能轨道中学习深度学习,来如何构建深度学习模型。您将探索深度学习的基础知识,了解 Tensorflow 和 Keras 框架,并使用 Keras 构建多个输入和输出模型。
GPT 模型有无穷无尽的应用,您甚至可以根据特定数据对其进行微调,以创造更好的结果。通过使用转换器,您将节省计算、时间和其他资源的成本。
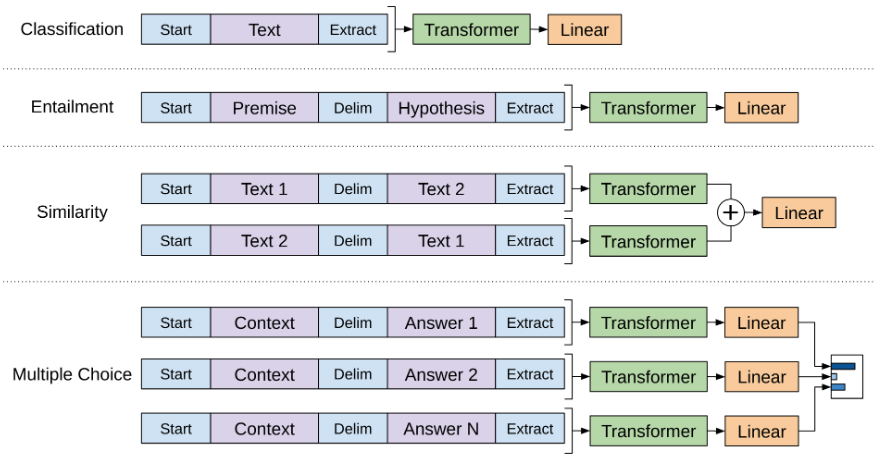
在 GPT-1 之前,大多数自然语言处理模型都是针对分类、翻译等特定任务进行训练的。它们都使用监督学习。这种类型的学习有两个问题:缺乏注释数据和无法概括任务。
GPT-4 有什么新功能?
在 AC10 线上见面会的问答环节中,OpenAI 的 CEO 山姆奥特曼 证实了关于推出 GPT-4 模型的传闻。根据他的说法,GPT-4 不会比 GPT-3 大很多。因此,我们可以假设它将有大约 175B-280B 个参数,类似于 Deepmind 深度思维的语言模型Gopher。
大型号Megatron NLG比GPT-3大三倍,参数530B,性能没有超过。紧随其后的较小型号达到了更高的性能水平。简单来说,大尺寸并不代表性能更高。
山姆奥特曼 表示,他们正专注于让更小的模型表现更好。大型语言模型需要庞大的数据集、海量的计算资源和复杂的实现。对于许多公司来说,即使部署大型模型也变得不划算。
最优参数化:大型模型大多优化不足。训练模型的成本很高,公司必须在准确性和成本之间做出权衡。例如,尽管有错误,GPT-3 只训练了一次。由于无法承受的成本,研究人员无法执行超参数优化。
微软和 OpenAI 已经证明,如果他们用最佳超参数对 GPT-3 进行训练,则可以对其进行改进。在调查结果中,他们发现具有优化超参数的 6.7B GPT-3 模型与 13B GPT-3 模型一样提高了性能。 他们发现了新的参数化 (μP),即较小模型的最佳超参数与具有相同架构的较大模型的最佳超参数相同。它使研究人员能够以一小部分成本优化大型模型。
最佳计算:DeepMind 最近发现,训练令牌的数量对模型性能的影响与大小一样大。自 GPT-3 以来,他们通过训练Chinchilla一个 70B 模型证明了这一点,该模型比 Gopher 小四倍,比大型语言模型多四倍数据。
可以安全地假设,对于计算优化模型,OpenAI 将增加5万亿个训练代币。这意味着它需要比 GPT-3 多 10-20 倍的 FLOPs 来训练模型并达到最小损失。
GPT-4 将是纯文本模型
在问答环节,山姆奥特曼 表示 GPT-4 不会像 DALL-E 那样是多模式的。这将是一个纯文本模型。
这是为什么?与仅使用语言或仅使用视觉相比,很难构建良好的多模式。结合文本和视觉信息是一项具有挑战性的任务。这也意味着它们必须提供比 GPT-3 和 DALL-E 2 更好的性能。
因此,不会期待 GPT-4 有任何花哨的东西。
稀疏度
稀疏模型使用条件计算来降低计算成本。该模型可以轻松扩展超过 1 万亿个参数,而不会产生高昂的计算成本。它将帮助我们在较低的资源上训练大型语言模型。但GPT-4不会使用稀疏模型。为什么?过去,OpenAI 一直依赖密集的语言模型,他们不会增加模型的大小。
人工智能对齐
GPT-4将比GPT-3更加一致。OpenAI 正在努力解决 AI 对齐问题。并希望语言模型遵循他们的价值观。 他们通过训练 InstructGPT 迈出了第一步,它是一个GPT-4模型,根据人类反馈进行训练以遵循指令。评委们认为该模型优于GPT-3,无论语言基准如何。
GPT-4 发布日期
OpenAI 还没有透露任何关于发布日期、模型架构、大小和数据集的具体信息,GPT-4的发布日期仍未确定,你可能会在明年或下个月看到它。下一个版本会解决旧版本的问题,呈现出更好的效果。
结论
GPT-4将是一个纯文本的大型语言模型,在与 GPT-3相似的大小上具有更好的性能。它还将更加符合人类的命令和价值观。
与 GPT-3 一样,GPT-4 将用于代码生成、文本摘要、语言翻译、分类、聊天机器人和语法校正等各种语言应用。新版本的模型将更安全、更少偏见、更准确、更一致,它还将具有成本效益和稳健性。

·END·

东八区8848
您的关注是我们更新的动力
长按识别二维码关注我们
排版:DBQ-8848
图片:BTC-1001
文字:Chunxiao
字体:默认字体
封面:MIMI
贴图:マッチ