自然语言处理任务系列——文本纠错
作者简介
作者:NLPerson
原文:https://zhuanlan.zhihu.com/p/545510251
转载者:杨夕
推荐系统 百面百搭地址:
https://github.com/km1994/RES-Interview-Notes
NLP 百面百搭地址:
https://github.com/km1994/NLP-Interview-Notes
NLP 论文学习笔记:
https://github.com/km1994/nlp_paper_study

01 相关概念
很多自然语言处理落地场景都会涉及到文本纠错的相关技术,例如跟各种形式机器人的语音或者文字对话,或者用手机扫描相关的PDF或者图片,或者跟人聊天时用输入法打字等等,无论是通过ASR识别的语音信息,通过OCR识别得到的图片信息,还是用户真实通过输入法的文字,都有可能出现错误。这些错误会影响文本的可读性,不利于人和机器的理解,如果这些错误不加处理,会传播到后续的环节,影响后续任务的效果。
常见的文本错误类型: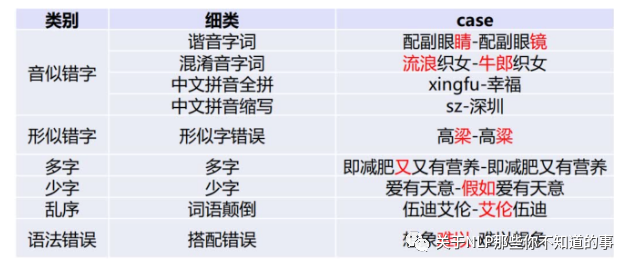
在不同的场景下出现的不同的错误类型的占比也不尽相同,但是无论哪种错误,都会影响文本的质量,妨碍人或者机器的阅读理解。而NLP的大部分模型都是通过高质量的中文数据训练得到的,训练语料中没见过这些错误类型,所以如果推理时的文本输入带有这些错误,一定程度上会影响模型的理解,从而使得模型的推理效果大打折扣。
02 模型综述
【EMNLP2018】A Hybrid Approach to Automatic Corpus Generation for Chinese Spelling Check https://github.com/wdimmy/Automatic-Corpus-Generation
介绍:本文由腾讯AI Lab主导,与清华大学和腾讯SNG合作完成。中文错字的自动检查是一个富有挑战又十分有意义的任务,该任务不仅用于许多自然语言处理应用的预处理阶段,而且可以极大促进人们的日常读写。数据驱动的方法在中文错字检查十分有效,然而却面临着标注数据缺乏的挑战。这个工作提出了一种自动构造用于拼写检查数据集的方法,分别通过基于OCR和SR的方法构造视觉上和听觉上相似的字来模拟错字。利用本文提出的方法,研究人员构造了一个大规模的数据集用于训练不同的错字自动检查模型,在三个标准的测试集上的实验结果证明了本文自动构造数据集方法的合理性和有效性。
效果:
【EMNLP2019】FASPell: A Fast, Adaptable, Simple, Powerful Chinese Spell Checker Based On DAE-Decoder Paradigm https://github.com/iqiyi/FASPell
介绍:基于BERT掩码语言模型的微调,利用训练语料(错误-正确句子对),微调BERT模型。对于无错误的句子和bert一样构造数据,即选出15%的tokens预测,80%用[Mask]替换,10%用保持不变,10%用随机token替换。对于有错误的句子,有错误的位置为需要预测的位置,标签是对应正确的token;
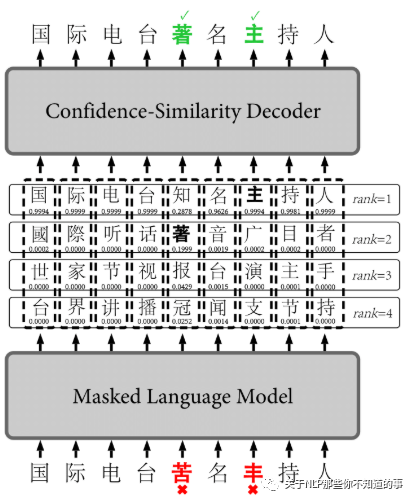
性能:在SIGHAN15测试集上的效果如下:
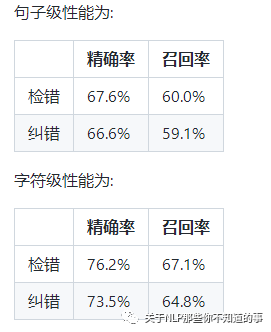
这意味着10个错误检测/纠正中大约7个是正确的,并且可以成功检测/纠正10个错误中的6个。
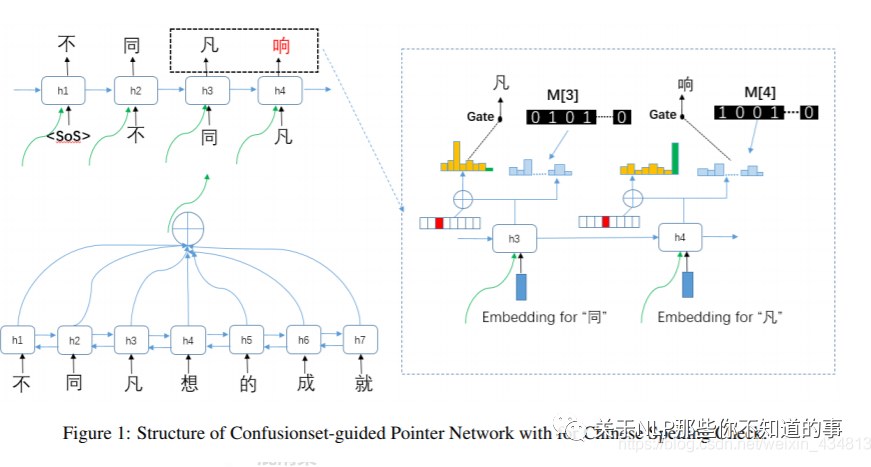
【ACL2019】Confusionset-guided Pointer Networks for Chinese Spelling Check https://github.com/sunnyqiny/Confusionset-guided-Pointer-Networks-for-Chinese-Spelling-Check
介绍:提出了使用混淆集和门控机制相结合的中文纠错模型。纠错模型使用的时Encoder-Decoder模式,编码器使用的是BiLSTM,对中文文本按字符级别进行编码,解码器使用的是LSTM,在解码器进行解码时,不仅接收上一个token的embedding的特征向量,还接受通过注意力机制将编码器的文本特征聚合成一个包含上下文信息的特征向量,从而达到基于语义信息的文本纠错。
【ACL2020】SpellGCN:Incorporating Phonological and Visual Similarities into Language Models for Chinese Spelling Check https://github.com/ACL2020SpellGCN/SpellGCN
介绍:
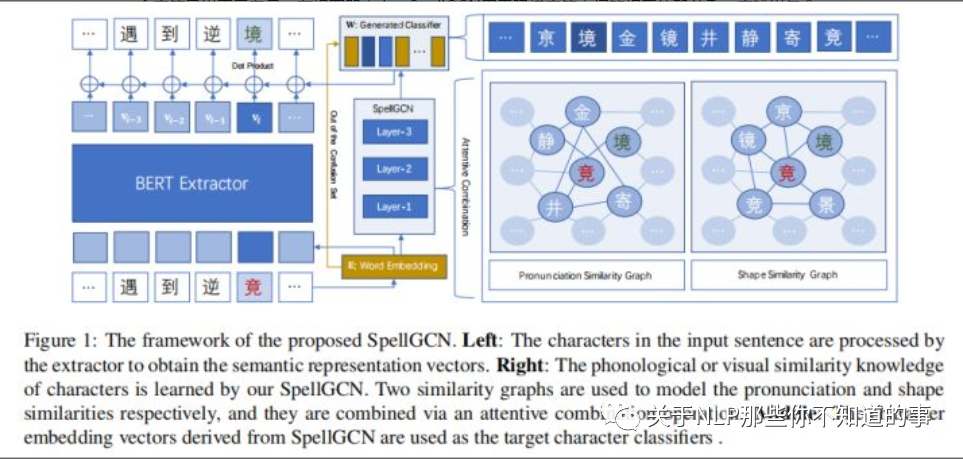
作者提出了通过一个特殊的图神经网络(SpellGCN)将音似和形似的知识融合进语言模型,该模型构建了字符之间的一张图,SpellGCN通过学习将这张图映射到一组相互依赖的字符分类器上。
然后,将这些分类器应用到从BERT中提取的文本表示上,并能够使整个网络进行端到端的训练。
SpellGCN能够捕获发音和字形的相似性,并能够探索字符之间的先验依赖。
尤其是,基于发音和字形之间的关联构造两张相似性图。
SpellGCN将两张图作为输入,并在相似字符交互作用之后,为每个字符生成一个向量表示。
然后,这些向量表示被构造成一个字符分类器用于BERT输出的语义表示上。
【ACL2020】Spelling Error Correction with Soft-Masked BERT https://github.com/hiyoung123/SoftMaskedBert
介绍:
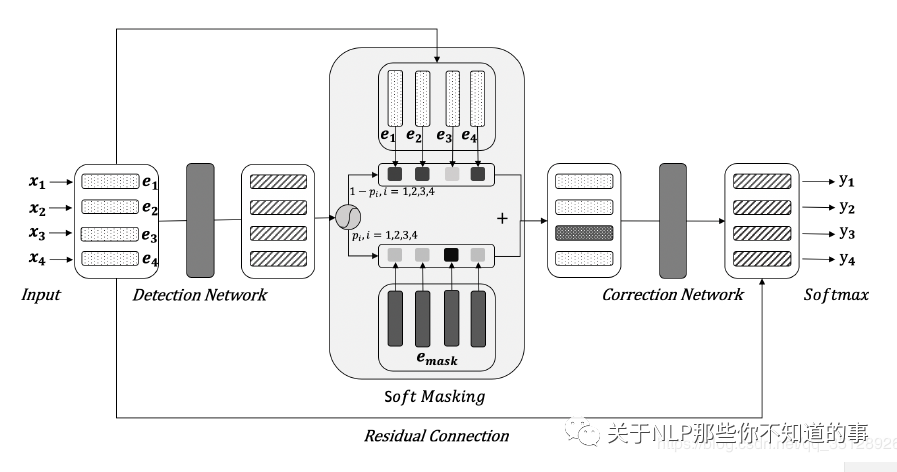
本文提出的Soft-Masked Bert这种新的神经网络架构,包含两部分,检测网络和基于Bert的纠错网络。
纠错网络与单纯使用Bert的方法类似。
检测网络是一个Bi-GRU网络,预测每个位置的字符为错别字的概率。
然后利用这个概率进行对该位置的字符嵌入进行soft masking(软掩码),Soft masking是hard masking的扩展,即当错误概率为1时,soft masking会退化为hard masking. 然后每个位置的soft-masked embedding输入到纠错网络,纠错网络使用Bert进行拼写纠错。
【ACL2021】PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction https://github.com/liushulinle/PLOME
介绍:
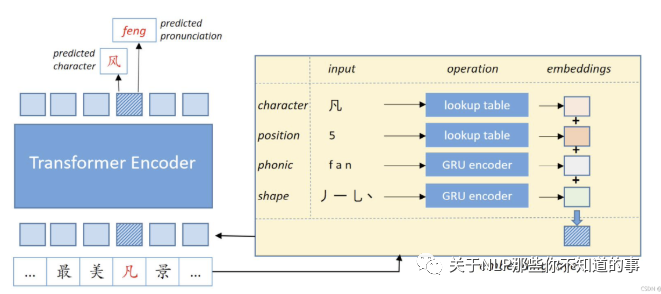
针对汉语拼写改正问题,提出了一种具有误拼知识预训练掩蔽语言PLOME。
以下特点使得具有误拼知识预训练掩蔽语言模型比普通的BERT用于中文拼写校正(CSC)更有效。
首先,提出了基于混淆集的掩蔽策略,其中根据混淆集,而不是BERT中的固定Token进行[MASK],将每个选择的Token随机地替换为类似的字符。
因此,PLOME掩蔽语言模型在训练前共同学习语义和误拼知识。
其次,该模型以每个字符的笔画和语音作为输入,使预先训练的带有错误拼写知识的掩蔽语言模型能够模拟任意字符之间的相似性。
最后预训练掩蔽语言模型与错误拼写知识通过联合恢复伪装符号的真实字符和语音,学习字符和语音水平的错误拼写知识。
【ACL2021】Dynamic Connected Networks for Chinese Spelling Check https://github.com/destwang/DCN
介绍:
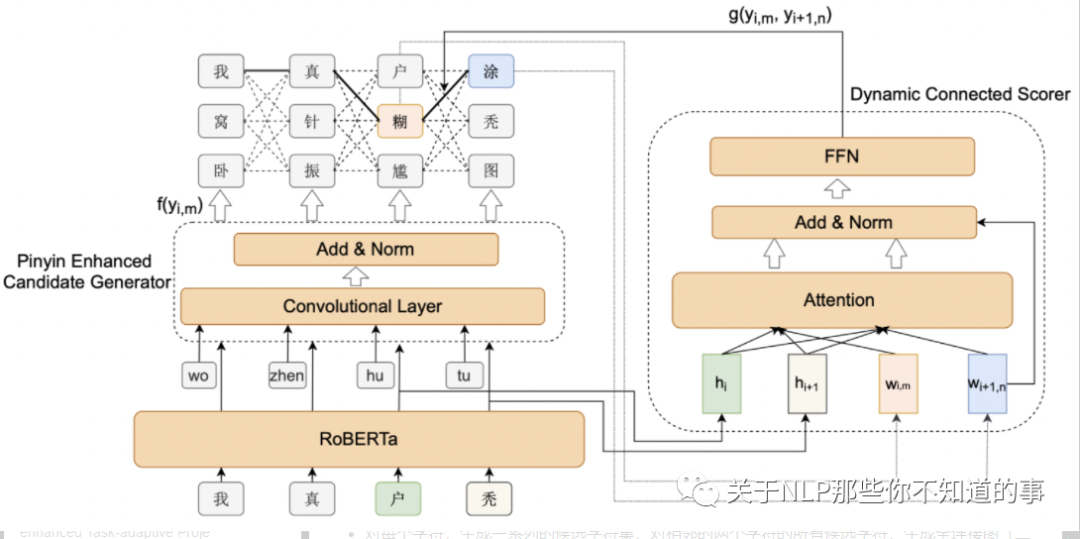
BERT是一种非自回归模型,其认为各个字符之间的独立无关的,这样在进行文本纠错的时候,容易导致不连贯问题。
为了解决这个问题,提出一种动态连接网络(DCN),其可以为邻接的字符构建依赖;
另外作者认为CRF也可以构建输出的依赖,但是并不能应用于语言模型或CSC问题,其认为CSC更需要获得上下文信息,而不是更复杂的label与字符之间的关系。
还提出简单有效的拼音增强的候选生成器,将语音信息融入到候选生成中。
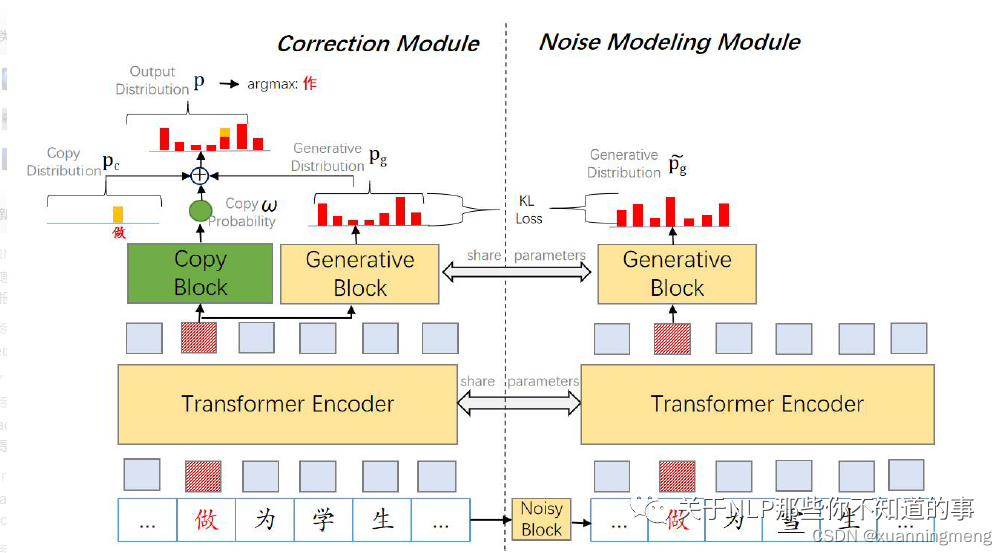
【ACL2022】CRASpell: A Contextual Typo Robust Approach to Improve Chinese Spelling Correction https://github.com/liushulinle/CRASpell
介绍:
在CSC任务上的SOTA,针对基于bert预训练模型的CSC的模型存在的问题:
在多错误文本上模型效果不好,通常在拼写错误的文本,拼写错误字符至少出现1次,这会带来噪声,这种噪声文本导致多错字文本的性能下降;
由于bert掩码任务,这些模型过度校正偏向于高频词的有用表达词。
CRASpell模型每一个训练样本构建一个有噪声的样本,correct 模型基于原始训练数据和噪声样本输出更相似的输出,为了解决过度校正问题,结合了复制机制来使得我们的模型在错误校正和输入字符根据给定上下文都有效时选择输入字符。
03 工业界落地案例
Pycorrector【https://github.com/shibing624/pycorrector】
pycorrector通用纠错模块是github上的开源项目,它提供了一种规则式检错、纠错方案,该方法因逻辑清晰、不依赖大量标注样本从而较容易实现落地,因此为广大研究者提供了良好的借鉴意义。该模块在检错部分利用常用字典、混淆字典与传统语言模型共同判断当前位置是否有错。制订了如下规则:①当切词后的片段不在常用字典中或存在于混淆字典的映射对中时判定有错;②计算传统语言模型概率是否低于门限并判错。候选召回部分利用同音、同型召回候选字词,打分排序利用句子困惑度来计算候选词权重,从而对候选进行排序。该方案是面向通用领域开发的,思路简单、易实现,但在保险垂直领域中容易得到较差的表现。

百度纠错系统【https://ai.baidu.com/tech/nlp_apply/text_corrector】
百度纠错系统凭借其海量用户点击语料训练了基于深度学习的序列标注模型。
错误检测:在错误检测部分,它利用10TB的无监督语料预训练Transformer/Lstm + CRF模型,再利用对齐语料(错误句子→正确句子)进行有监督学习该序列标注模型;
候选召回:在候选召回部分,利用了对齐语料和对齐模型构建字级别、词级别、音级别的混淆字典,先利用字、音混淆字典初步召回候选,然后再利用词级别混淆字典和语言模型二次筛选候选,从而形成最终候选;
候选排序:利用上下文DNN特征和人工提取的形音、词法、语义等特征一起训练GBDT&LR的排序模型。

腾讯垂域的DCQC纠错框架
腾讯提出一套针对垂直业务的通用纠错框架-DCQC,由召回层和决策层两层组成。该方法可以方便扩展到其他领域。
召回层:每个领域建立属于自己的一个数据库,建立字和拼音两个维度的倒排索引,通过检索排序的方式召回一定量的候选;
决策层:人工提取用户特征、拼音特征等5种类型特征训练svm二分类模型用于候选排序。
滴滴ASR纠错【https://cloud.tencent.com/developer/news/735166】
滴滴司机语音助手可以通过语音交互的方式实现接单、查询天气、规划路线等能力,帮助司机解放双手。在司机语音助手项目中,目前支持的设置温度、查询天气等意图中的实体部分容易识别错,支持了这些实体词的纠错能力,在语音识别字准优化上,提升了绝对1%的字准确率,交互成功率平均提升7.24%。
保险垂域中文纠错
将纠错流程分解为错误检测+候选召回+打分排序三个关键步骤。
错误检测:为了解决资源受限问题以及音近错误问题提出了基于字音混合语言模型的错误检测算法,该模型可以通过未标注的无监督原始语料进行训练,同时利用字音混合特征限制了预测概率分布;
候选召回:结合双数组字典树及CSR存储架构优化了整体字典存储方案,同时优化了内存空间及索引效率;
此外又提出创新性的编辑距离召回算法,利用分层思想重构了倒排索引字典存储方式,使得基于编辑距离的搜索变得灵活而高效。
最后,在候选排序方面我们加入了语言模型预测的语义特征,从而提高了模型的判别能力。
04 相关搜索
文本纠错模型综述//文本纠正模型综述//中文文本纠错概述//文本纠错应用案例//文本纠错相关模型//文本纠错最新研究进展//文本纠错最新论文//文本纠错落地案例//文本纠错模型代码//文本纠错相关论文汇总//文本纠错 github//文本纠错模型代码汇总